You could have the fastest website with the greatest content in human history, but if Google doesn’t index it, no one’s going to see it.
So, how do you know if Google’s indexing your pages, and what can you do about it if they’re not?
What is the Google Index?
Probably the best analogy for the way search engines work is a library. If you wanted to find books on a subject, you’d go to the card catalog to find a list of books they had on the topic:
Google works in essentially the same way. When you look for something on Google, you aren’t searching through the actual web - you’re digging through Google’s card catalog. Google then returns a bunch of cards it thinks are relevant to the query in the form of the search engine results page.
Google builds its index by clicking links out on the web (crawling), recording information about the pages it lands on and storing that information in its index (indexing).
So you can see why making sure your website gets crawled and indexed is really important for SEO. No matter how good your pages are, if they aren’t in the catalog, Google can’t show them.
Is Your Site Indexed?
There’s a couple of ways you can check to see if your website has been indexed. For Pro and Premium WooRank members, your Review includes the Discovered pages criteria. This section is the number of pages we’ve found in Google’s index.
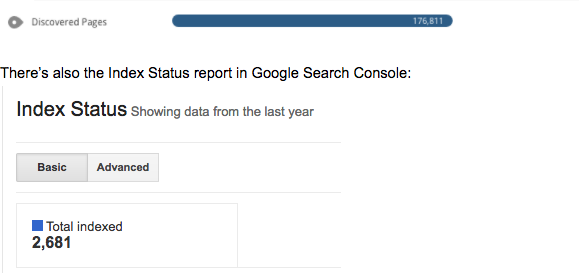
There’s also the Index Status report in Google Search Console:
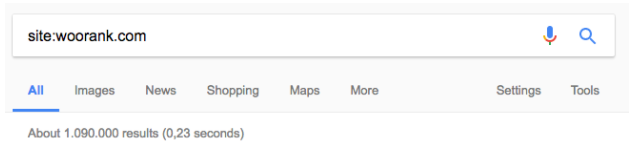
There’s also the site: search operator. Just do a quick Google search for "site:example.com", entering your website instead of “example.com.” This will give you a rough idea of how many pages Google has indexed on your domain.
Last but not least, you can check the index status of individual pages by using the cache: search operator. Just search for an individual page with "cache:" in front of it (no spaces!) to see the most recent version of the page as indexed by Google.
What’s Keeping Google From Indexing Your Pages?
You’ve checked your Review, or your Index Status report, and it’s showing way fewer pages than you have on your website. You’ve got a crawling and/or indexing problem. What causes these problems?
You probably won’t like this answer: It could be a lot of different reasons. Many of them are very technical.
But here’s an answer you will like: it doesn’t have to be hard, complicated or even all that technical to find out. You just need a good SEO crawler. And what do you know? WooRank’s Site Crawl can find those complicated, technical reasons for you.
You’re telling Google not to
There are certain things that can be on your site or on individual pages that tell Google to ignore a page. The issue could be that your robots.txt has disallowed that page or folder by accident. Or you could have accidentally added a "NoIndexed" robots meta tag to a page.
To find these pages, open up Site Crawl and head to the "Indexing" section. This area of the analysis will show you pages that:
- Are disallowed by robots.txt
- Have a NoFollow robots meta tag (or HTTP header)
- Are hosted on a non-canonical (more on that later) version of your URL

Site Crawl will also tell you if the non-indexable page appears in your sitemap. Sitemaps don’t make a page non-indexable, but leaving a page off the sitemap does make it a lot harder for Google to find.
However, robots.txt and nofollow tags aren’t the only ways you could be telling Google not to index your content.
Canonical tags are used to point search engines at the version of a page you want them to consider the original, or "canonical," version of a page. Canonical tags help deal with duplicate content and consolidate link juice.
So you can see how messing up your canonical tags can cause Google to skip crawling the page you want indexed.
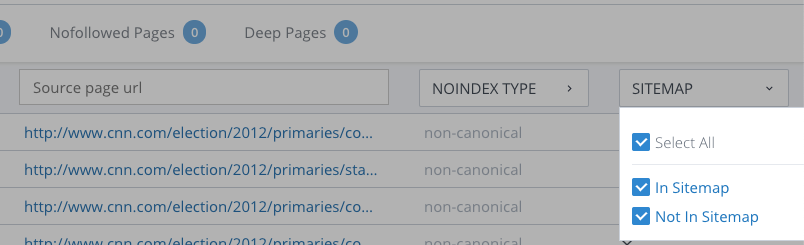
Canonical problems that can cause a page to not get indexed include:
- Tags that link to a broken page
- Multiple canonical tags on one page
- Canonical URLs that don’t match the URL in your sitemap
Site Crawl will identify these instances and help you find where your canonical tags are telling Google not to index a page.
Your pages (or links) are broken
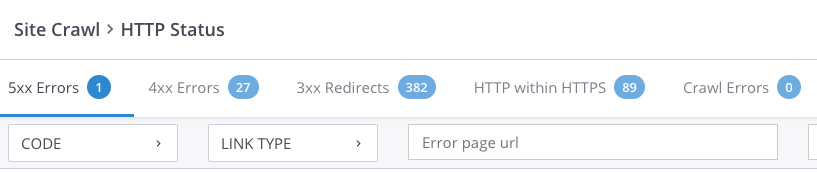
If a page doesn’t load, a page doesn’t get indexed. And because Google finds new pages by following links, a broken link means Google is less likely to crawl the destination page. That’s why Crawl’s analysis includes a list of pages that return HTTP errors that prevent Google from accessing them:
- 5xx: Servers return status codes in the 500s when it encounters an error, generally on the server end. This includes timeouts and server overload.
- 4xx: Servers return status codes in the 400s when the client (web browser) makes an invalid request. The 404 not found error is the most well-known error of this type.
- 3xx: Codes in the 300s indicate a redirect. These are technically not errors, but using them incorrectly can mean Google won’t access a page. URLs that redirect to broken URLs obviously won’t get indexed, but Google could also decide not to index pages in redirect chains. Catching Google in a redirect loop also means it won’t crawl or index a page.
You’ve got some on-page SEO issues
Google’s mission is to provide the best search results based on a user’s query. So it’s not super interested in keeping pages it sees as bad search results in its index. One of the big on-page problems that will keep a page from getting indexed is duplicate content.
You probably know if your website has the most obvious examples of duplicate content: scraping and plagiarism. But, unfortunately, you could create duplicate pages by accident, without ever knowing it. Fortunately for you, Site Crawl has the ability to find duplicated pages, as well as instances where non-duplicate pages could look like copies of each other.
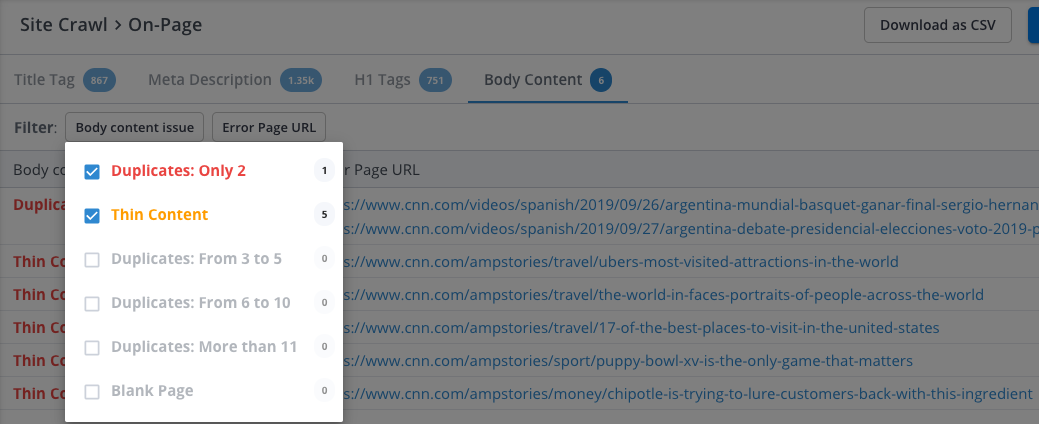
If you head to the Body Content Issues section, you’ll find pages Site Crawl found that have duplicate body content. These types of pages are usually caused by list sorting, pagination or other dynamic URL parameters.
However, you could also have pages with different page content that still look the same. How?
- Title tags: Page titles should be an introduction to what’s on a page. And since each of your pages has unique content, Google could see duplicate titles as signs of copied content.
- Meta descriptions: Just like titles, each page should have unique descriptions to go with its unique content.
Look at the URLs of the pages with duplicate titles and/or descriptions. Depending on how many copies there are, you could have a template issue or simply got a little carried away with ctrl+v.
Indexing is Just the First Step!
Making sure that Google is finding, crawling and indexing your website is a vital step 1, but it's not a one-step process. Now that Google is indexing your site, ensure that your pages are optimized to be found by your audience.