Utilisation du Site Crawl
Les résultats de l'exploration vous indiquent tous les éléments importants de votre site et vous informent des problèmes pouvant affecter votre référencement :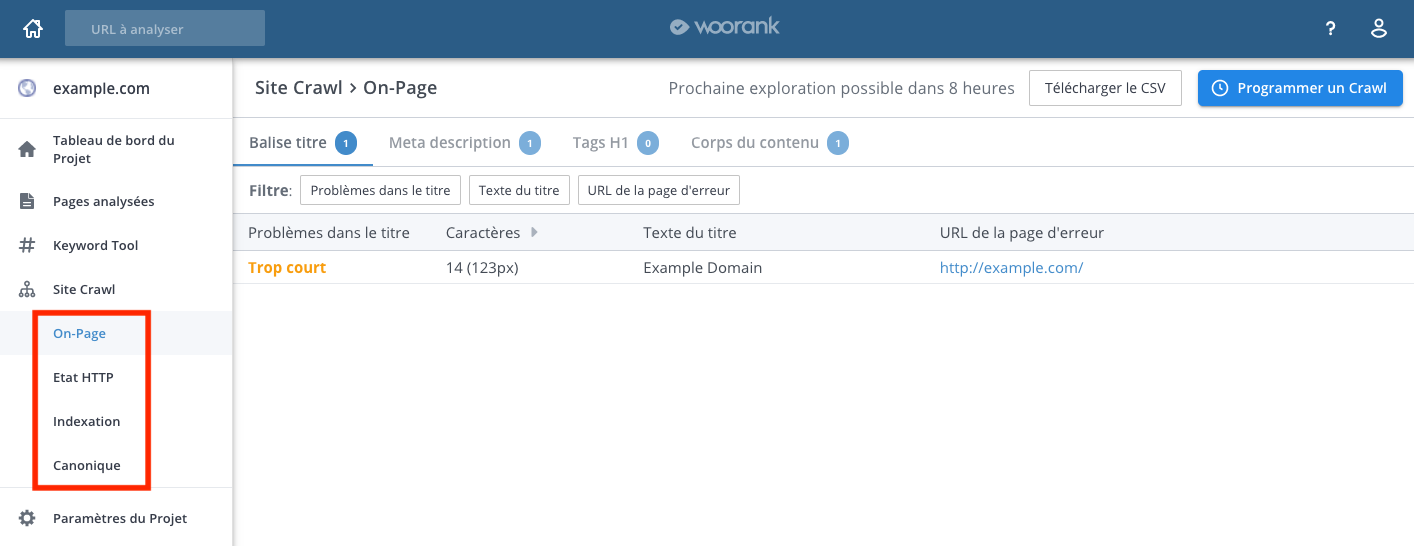
- On-page : Meta descriptions, balises HTML, headers et contenu sont explorés pour identifier les pages dupliqués ou non-optimisées
- Etat HTTP : Les liens et les pages sont explorés afin d’identifier les pages et les liens qui renvoient des codes de statut HTTP susceptibles d’affecter l'accessibilité et l’ergonomie de votre site, tels que des liens cassés, des boucles et des chaînes de liens
- Indexation : Les pages qui ne peuvent pas être explorées ou indexées sont répertoriées dans cette section. Cela peut être intentionnel, ou le résultat d'erreurs dans les balises robots.txt ou NoIndex.
- Canonique : Les balises Canonical et Hreflang sont explorées pour s'assurer qu'elles redirigent vers les pages fonctionnelles répertoriées dans votre SiteMap.
Pour obtenir plus d'informations sur les erreurs localisées pour chaque section, vous pouvez cliquer sur '?' situé en haut à droite de votre page afin d'activer les aides contextuelles :