La gran mayoría del SEO está orientado a realizar acciones que harán que tus páginas web estén mejor posicionadas en los resultados de búsqueda de Google. Sin embargo, lo bien que el SEO funcione depende realmente de una sola cosa: que Google indexe tu sitio web.
Puedes tener el sitio web más rápido con el mejor contenido en la historia de la humanidad, pero si Google no la indexa, nadie va a verla.
Entonces, ¿cómo puedes saber si Google está indexando tus páginas web y qué puedes hacer al respecto si no lo está haciendo?
¿Qué es la indexación de Google?
Probablemente la mejor analogía para el funcionamiento de los motores de búsqueda es una biblioteca. Si querías encontrar libros sobre un tema, ibas al catálogo para encontrar una lista de libros que tenían sobre el tema.
Google funciona esencialmente de la misma manera. Cuando buscas algo en Google, no estás buscando en la web, sino en el catálogo de Google. Google devuelve un montón de respuestas que considera relevantes para tu consulta en forma de página de resultados del motor de búsqueda. Google crea su índice haciendo clic en los enlaces de la web (crawling), registrando información sobre las páginas en las que se encuentra y almacenando dicha información en su índice (indexación).
Por este motivo puedes imaginarte por qué asegurarte de que tu página web es rastreada e indexada es muy importante para el SEO. No importa lo buenos que sean tus sitios, si no están en el catálogo, Google no puede mostrarlos.
¿Está indexado tu sitio?
Hay un par de maneras de comprobar si tu sitio web ha sido indexado. Para los usuarios Pro y Premium de WooRank, los Proyectos incluyen los criterios de las páginas descubiertas. Esta sección es el número de páginas que hemos encontrado en el índice de Google. También está el Estado de Indexación de Google Search Console:
También está el Estado de Indexación de Google Search Console:
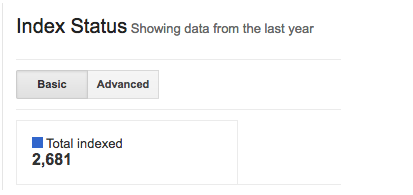
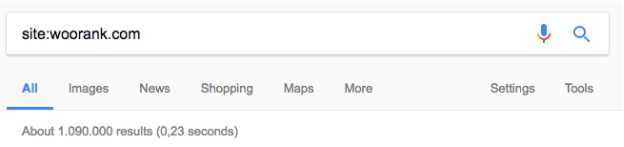
Puedes hacerlo también con el operador de búsqueda "site": Solo tienes que hacer una búsqueda rápida en Google escribiendo "site:example.com", e introduciendo tu web en lugar de "example.com". Esto te dará una idea aproximada de cuántas páginas ha indexado Google en tu dominio.
Por último, pero no por ello menos importante, puedes comprobar el estado del índice de cada una de las páginas usando el operador de búsqueda cache: Simplemente busca una página cualquiera introduciendo "cache:" delante (sin espacios) para ver la versión más reciente de la página indexada por Google.
¿Qué está impidiendo que Google indexe tus páginas?
Has revisado tu Proyecto, o tu informe de Estado de Indexación, y muestra muchas menos páginas de las que tiene tu página web. Tienes un problema de crawling o de indexación. ¿Qué causa estos problemas
Probablemente no te guste la respuesta: puede ser por muchas razones diferentes. Muchas de ellas son muy técnicas.
Pero he aquí una respuesta que sí te gustará: la solución no tiene por qué ser difícil, complicada ni demasiado técnica. Solo necesitas un buen SEO crawler. ¿Y cómo se consigue? El Site Crawl de WooRank puede encontrar estas complicadas razones técnicas en tu lugar.
Le estás diciendo a Google que no
Hay ciertas cosas que puede haber en tu web o en una de sus páginas que le están diciendo a Google que la ignore. El problema podría ser que tu archivo robots.txt haya rechazado esta página o carpeta accidentalmente. O puede que hayas añadido accidentalmente una metaetiqueta robots "NoIndexed" a una página.
Para encontrar estas páginas, abre Site Crawl y dirígete a la sección "Indexación". Esta parte del análisis te mostrará las páginas que:
- Están rechazadas por robots.txt
- Tienen una metaetiqueta robots NoFollow (o cabecera HTTP)
- Están alojadas en una versión no canonical de tu URL (más información más adelante)

Site Crawl también te indicará si la página no indexable aparece en el mapa del sitio web. Los mapas del sitio no hacen que una página no sea indexable, pero el hecho de dejar una página fuera del mapa del sitio hace que a Google le resulte mucho más difícil de encontrar.
Sin embargo, robots.txt y etiquetas NoFollow no son la única forma de decirle a Google que no indexe tu contenido.
Las etiquetas canonicales se utilizan para dirigir los motores de búsqueda a la versión de una página que quieres que sea considerada la versión original o "canonical" de una página. Las etiquetas canonicales ayudan a lidiar con el contenido duplicado y a consolidar los enlaces.
De este modo, es fácil de entender cómo la alteración de las etiquetas canonicales puede hacer que Google se salte el crawling de la página que deseas indexar.
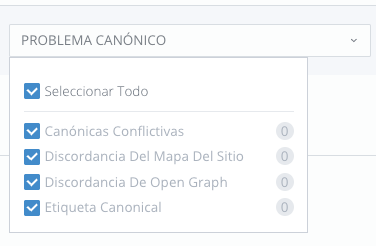
Los problemas canónicos que pueden causar que una página no sea indexada incluyen:
- Etiquetas que enlazan a una página rota
- Múltiples etiquetas canonicales en una página
- URL canonicales que no coinciden con la URL de tu mapa del sitio.
Site Crawl identificará estas instancias y te ayudará a encontrar en qué punto tus etiquetas canonicales le están indicando a Google que no indexe una página.
Tus páginas (o enlaces) están rotos
Si una página no carga, no se indexa. Además, dado que Google encuentra nuevas páginas a través de enlaces, un enlace roto significa que es menos probable que Google rastree la página de destino. Por eso el análisis de Site Crawl incluye una lista de páginas que devuelven errores HTTP que impiden a Google acceder a ellas:
- 5xx: Los servidores devuelven un código de estado del tipo 500 cuando encuentran un error, generalmente del lado del servidor. Esto incluye tiempos de espera y sobrecargas del servidor.
- 4xx: Los servidores devuelven códigos del tipo 400 cuando el cliente (navegador web) hace una solicitud incorrecta. El error 404 no encontrado es el error más conocido de este tipo.
- 3xx: Los códigos del tipo 300 indican una redirección. Estos no son técnicamente errores, pero su uso incorrecto puede significar que Google no accederá a una página. Las URL que redireccionan a URL rotas obviamente no se indexarán, pero Google también podría decidir no indexar páginas en cadenas de redireccionamiento. Si Google entra en un bucle de redireccionamiento, no rastreara ni indexará la página.

Tienes algunos problemas de SEO on-page
El objetivo de Google es proporcionar los mejores resultados de búsqueda basados en la consulta de un usuario. Por eso no es aconsejable mantener páginas que interpreta como malos resultados de búsqueda en su índice. Uno de los grandes problemas on-page que hacen que una página no se indexe es el contenido duplicado.
Probablemente sabrás si tu página web contiene los ejemplos más obvios de contenido duplicado: el scraping y el plagio. Pero, desafortunadamente, también puede que crees páginas duplicadas accidentalmente, sin siquiera saberlo. Afortunadamente, Site Crawl tiene la capacidad de encontrar páginas duplicadas, así como casos en los que algunas páginas no duplicadas puedan parecer copias de otras.

Si te diriges al apartado Problemas de contenido, encontrarás las páginas en las que Site Crawl ha detectado contenido duplicado. Este tipo de páginas suelen deberse a la ordenación de listas, la paginación u otros parámetros dinámicos de URL, y pueden corregirse mediante la herramienta Parámetros de Google y/o etiquetas canonicales.
Sin embargo, también puede haber páginas con distinto contenido que sigan pareciendo iguales. ¿Cómo?
- Etiquetas de título: Los títulos de las páginas deben ser una presentación de lo que hay en una página. Y como cada una de tus páginas tiene un contenido único, Google puede interpretar los títulos duplicados como signos de contenido copiado.
- Metadescripciones: Al igual que los títulos, cada página debe tener descripciones únicas que acompañen a su contenido único.
Mira las URL de las páginas con títulos y/o descripciones duplicadas. Dependiendo de cuántas copias haya, puede que tengas un problema con las plantillas o que te dejaste llevar demasiado usando el Ctrl+V.
¡La indexación es solo el primer paso!
Asegurarse de que Google busca, rastrea e indexa tu página web es un primer paso vital, pero no es un proceso de un solo paso. Ahora que Google está indexando tu web, asegúrate de que tus páginas están optimizadas para que tu público las pueda encontrar.