If you own a business, or have a website with the purpose of making money, SEO is for you. But you’re not a marketer — like an NCAA athlete, you’ve gone pro in something else. And there’s a lot that goes into effective SEO.
You’ve got…
- Keywords
- Backlinks
- Technical SEO
- Content marketing
- User experience
Man, that sounds like a lot of work. But what if there’s a way to make it all easier for yourself?
Well, if you’ve got an SEO crawler, there is.
What is an SEO Crawler?
In the context of SEO, “crawler” and “crawling” can mean a couple of different things, depending on the context. When discussing search engines (like Google), crawlers refers to the programs that navigate the web, following links from page to page. Crawling refers to a search engine’s bots finding and reading the page they land on.
After crawling a page, in a step called “indexing,” search engines store a copy and some information about it on their servers. The end goal of technical SEO is to make your pages more accessible and easier to index for search engine crawlers.
However, there are crawlers out there other than Google (or Bing, or Baidu, or Yandex…). SEO crawlers work the same way as search engine crawlers. They follow links around a website collecting information about the pages they encounter. The difference is that these crawlers don’t index the pages.
Instead, they output the data they collect for marketers to use when improving their technical SEO.
Basically, SEO crawlers and tools used by search marketers to look at a website through the eyes of Googlebot.
What Will Crawling a Site Uncover?
So, as we just mentioned above, using an SEO crawler for your website is like putting on a pair of Googlevision glasses when you look at your website. A good SEO crawler is a powerful tool to uncover all sorts of problems with your site’s technical SEO and content.
Issues like…
Duplicate Content
One of the great fears in SEO, duplicate content is a whole subject unto itself. The fact is, there are a lot of ways to wind up with duplicate content on your website entirely accidentally (something you’ve probably picked up on if you read this blog with any frequency).
You can wind up with duplicate content due to
- Paginated lists
- The same product available in multiple colors or sizes
- Template issues causing duplicated titles or descriptions
- Different pages in the same language targeting different geographies
- CMS errors
Individually, these problems aren’t all that hard to find and fix. Just add the rel="prev”/”next” tags to your paginated list to fix that problem, or add a 301 redirect to your site when you move a page.
But about those sites that have lots of pages, lots of pagination, lots of products?
You need a crawler to find those problems.
When you do encounter accidental duplicate content, fix it by adding a canonical tag and/or redirecting to that page.
And a good SEO crawler will check that for you, too. Canonical tags that don’t match sitemap URLs, or point to 404 pages, don’t do you any good, so if your tool doesn’t find these tags, it’s not much help.
Here’s WooRank’s Site Crawl detecting that a website doesn’t have any broken canonical URLs:
Indexing Issues
The whole reason crawlers exist is to figure out how indexable your website is. So a good SEO crawler will find errors in your pages’ indexability.
Note: These problems include both pages you want to get indexed and those you don’t.
Using robots.txt and the meta robots tag is one way to keep pages you don’t want Google to index out of search results. But if you don’t use them right you can wind up with people seeing pages you don’t want them to while other pages are ignored entirely.
The results of your SEO crawl should give you a list of pages that are disallowed via robots.txt and noindex tags. That way you can make sure all the right pages are in the right place.
Bad redirects
Redirects aren’t ideal – they slow down page speed – but they’re necessary when you need to move a page or migrate a whole website. The good news is that using 301 and 301 redirects will pass full link juice from both internal and external links.
Using 301s and 302s can still go wrong for your website. A couple of different ways, in fact:
- Broken redirects: Pretty self-explanatory, these are redirects that send users to broken or error pages.
- Redirect chains: One redirects pointing to a URL that also redirects forms a chain. Chains aren’t limited to just two, by the way. Chains are bad user experience and SEO because of the slow download time and, quite frankly, they make you look really untrustworthy.
- Redirect loops: Loops are formed when two pages point redirects back at each other, causing users to bounce back and forth between pages that never load. It’s the web designed by M.C. Escher.
Without your SEO crawler, you’d have to find all of those redirects yourself to test them. Again, not really feasible for the vast majority of website owners. However, with a tool like Site Crawl you can check all your links in a matter of hours.
Insecure pages
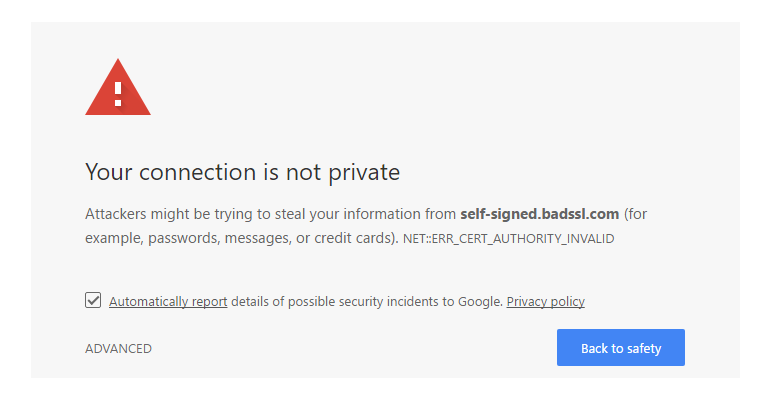
Security is of the utmost importance to your website, especially if you handle any sort of personal or financial information. It’s important to your users, and it’s important to Google. The problem arises when you don’t completely migrate everything from HTTP URLs to HTTPS ones.
When that happens, not only are your pages less secure, people will see big scary warning pages when they try to access them. Not only will these pages not get indexed, but they could also cause your whole domain to lose ranking power.
Plus, if you visit a website and see a security warning page, are you going to ever go back to that website?
Time for Keywords!
Alright, your website's technical aspects have all been set up and checked. You're good to go, right?
Not yet.
Now is the time to start looking at your on-page content to make sure you're getting the most value out of the way you're using keywords.