The last thing that you need is a penalty from Google. Unfortunately, sometimes you may actually have duplicate content on your site that you are unaware of. Some of it may be consumer-generated content, for instance where people write about their experiences with your product in product reviews. In this article, we define duplicate content, why it matters, what leads to it and how to solve it. This article will serve as your ultimate guide to duplicate content and SEO.
What is Duplicate Content?
Duplicate content can be defined as having the same content on different or across domains. Sometimes the content may be too similar. In such cases, Google only shows one of the domains in search results. Duplicate content became a serious consideration for sites in 2011 when Google launched the first Panda algorithm update. It’s now common sense that you should not have duplicate content. But, should you be concerned about duplicate content today?
Why is Duplicate Content Still a Big Deal?
Google filters duplicate content out of its search results.
Google indexes and shows distinct information in search results. The bots work on a concept referred to as filtering, where if there is duplicate content, for instance, the same article on two URLS, Google will only show one page in the results. That second URL is not necessary. It will not make your site rank higher in search results. Too much duplicate content on one domain may actually result in lower rankings and, sometimes, your site could be removed from the Google index.

How Does Duplicate Content Come About?
While some SEOs do try to use duplicate content to manipulate Google into ranking their sites higher, most duplicate content is accidental – the result of technical issues with a website. These problems can be hard to find, so an SEO crawler such as WooRank‘s Site Crawl will be your best friend here.
Let’s dive into these issues:
1. The URL
In a website database, one article can be accessed using different URLs. This article has only one unique identifier in the database, though. This one article can be accessed using different URLs, and search engines equate one URL to one article, in this case. While the reality is that there is only one article in the database, search engines “think” that the different URLs are actually duplicate content. Even though the URLs point to one article, not two articles with the same content.
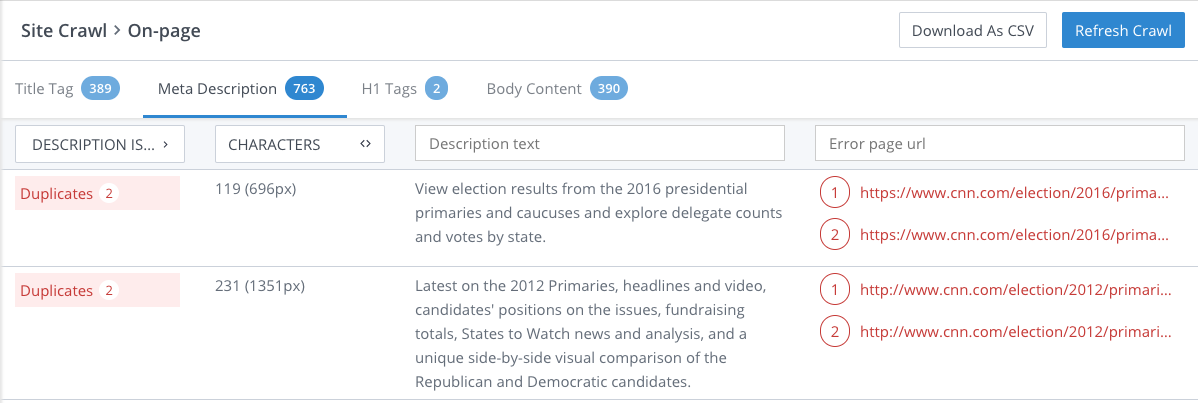
To fix this problem, you can explain this difference to your web developer and they will check whether there are several URLs that point to the same content in the database. They should also ensure that internal linking is consistent. No need to link to have links to, for instance,http://www.abc.com/page/ and http://www.example.com/page/index.htm.
2. Printer-friendly pages
There are content management systems that create different versions of the same content, usually “regular” and printer-friendly versions. If you link to the printer-friendly versions, for instance, Google will index these pages. If you have not blocked any of the versions with a “noindex meta tag”, Google will index both of them. Sometimes, both versions may be indexed, resulting in duplicate content.
Let’s see how you fix these duplicate content issues and more.
How to Fix Duplicate Content Issues
1. Homepage canonicalization
Canonicalization is indicating the preferred URL, where you have pages with very identical content. You are likely to find duplicated content on your home page. People are also highly likely to link to your homepage more than any other page. Homepage canonicalization is therefore very important. There are several ways to achieve canonicalization. Let’s look at them below:
a) The “rel=canonical” link element
The rel canonical is also known as a canonical tag. The tag tells search engines that a page should be treated as if it were a copy of a specified URL (for instance the home page). The search engines will, therefore, credit all the ranking factors to the home page, in this case.
The canonical tag is part of the HTML head on your web page. Ask your developer to add the rel canonical to the HTML head where there are duplicate pages. Replace the URL of the original page with a link to the canonical page.
Here is a general format of how the code looks:
<head>
...[other code that might be in your document's HTML head]...
<link href="URL OF ORIGINAL PAGE" rel="canonical" />
...[other code that might be in your document's HTML head]...
</head>
Replace “URL OF…” with a link to the canonical page (original link)
If you’re using WordPress, using a Header Footer Plugin can help you add the HTML tag to your heading section
b) 301 redirects
This is the other way to deal with duplicate content via canonicalization. A 301 redirect is created from the duplicate to the original content page. This “combines” all the duplicate pages into one, creating a stronger relevancy and popularity signal, which can only help your site to rank higher in search engines.

To set up 301 redirects, create a 301 permanent redirect instruction at the server level. Used .htaccess files in Apache, and the administrative console in IIS. It may also be a smart move to register any changes that you make to your website at Google Webmaster Tools.
2. HTTPs and Relative Linking
In order to understand these concepts, we need to understand something about URLs. You can have a URL that begins with HTTP and one that begins with HTTPS. The former is usually followed by “www”. The latter is not accompanied by www.
Understanding this distinction is important as it is one of the sources of duplicate content. If your non-www URL version does not redirect to your www URL version, then you have two versions of your website URLs, according to search engines. The same thing happens when your HTTPS does not redirect to your HTTP and vice versa. This means that your website will have two versions too. This means that it is possible to have 4 versions of your site, causing a serious duplicate content issue.
Where do relative links come in? Internal linking can compound the above mentioned duplicate content problem. There are two types of internal linking: relative and absolute linking. Let’s distinguish them and how they contribute to duplicate content.
You are using an absolute URL when you use the entire web address of the page that you are linking to in the link. During web development, internal links are coded with relative URLs. A page, for instance, is represented by “/page”. The browser is supposed to “understand that the relative URL points to a page that is on the same domain” (your website).
Internal linking is what results in your website having 4 different versions as discussed above. This means that you would need to build links that are four times as many for the same page authority. Remember, people will link to any of the four versions, and Google may pick any of them to rank in search results.
The other problem affects Google crawling. With four versions, Google is less likely to crawl your website deeply and frequently. It costs them money, and they will not want to keep spending it on one site. This means that your site will be crawled less frequently and therefore it will rank low on search results.
How then do you fix the relative URL problem?
The first thing that you need to do is ensure that the four versions of your website resolve to one. The best version to go for is the non-www HTTPS. Google says it is better. The second thing will be having your relative URLs changed to absolute URLs. Canonicalization will also help here if the internal links will not get fixed.
3. Mirrored sites
Also known as mirror sites, this refers to a copy of a site placed under a different URL. It contains basically the same content with the exception of a small detail like a contact number or email address. Usually, they are created to relieve server traffic and are used in different locations in a localized SEO context.
Mirrored sites create a duplicate content problem. Google does not know which URL to index. The best way to deal with mirrored sites is to use top-level domains where the content is country specific.http://www.abc.de indicates that the content is focused on a German audience. Better still, instead of a “copy-paste” of the same content under different domains, craft location-specific content. Communicate with people in different locations differently.
4. Tags and categories
WordPress is the main culprit when it comes to tags and categories that create duplicate content. WordPress creates several pages and if you do not use categories or tags properly, or if archived pages are not indexed rightly, it could result in duplicate content.
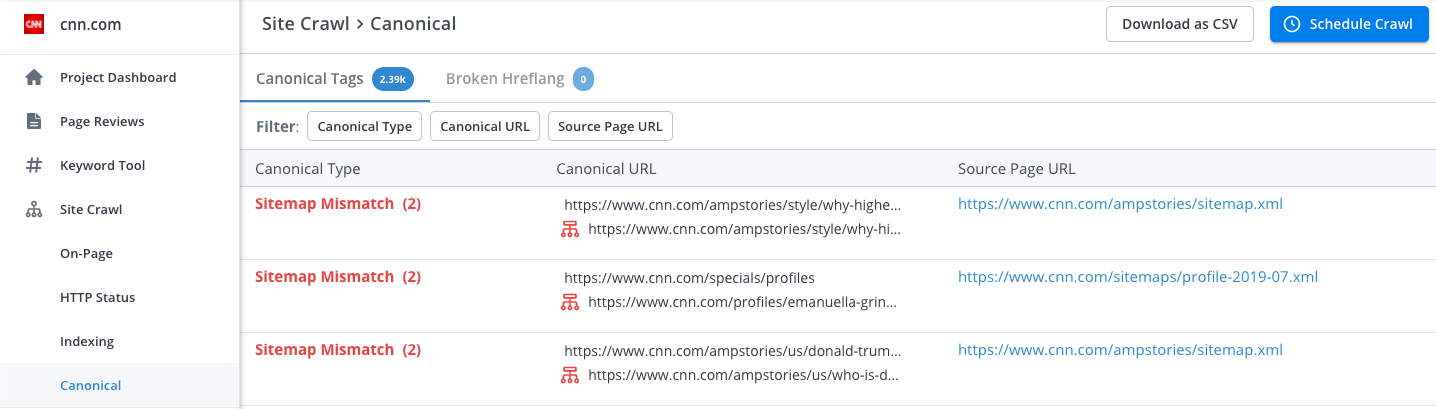
Tags and categories create duplicate content in a number of ways:
- Archives with one post that are the exact copy of the original
- Similar categories and tags which result in identical content
- Multiple category indexes that copy multiple times when using excerpts
- Over tagging posts
- Not using excerpts on archive pages, so they contain full posts
How to solve duplicate content issues caused by tags and categories:
- Use the Term Management Tools plugin to help merge tags and categories
- If you have tags with only one post associated with them, remove them until when you have more content to attribute to the same
- 301 directs
- Instruct search engines not to index category and tag archives
5. Search pages pagination
Pagination refers to splitting content into several pages and providing links usually at the bottom of the page, where you can go to the next or previous page or section. Sometimes you get to choose the page number that you want; a good example is Google search results. Pagination is frequently used on blogs and e-commerce sites. Many times, there is an option to “view all”, where you can see the content on one page.
Separate paginated and view all versions of the same content result in duplicate content. There are several ways to resolve this:
a) Canonicalization to a view-all version
If the paginated series has a view-all version, Google attempts to detect this. The paginated pages will be de-duplicated, instead of the view-all page. The best thing to do is to canonicalize the set of paginated pages to a view-all page.
b) Indicating pagination with HTML Markup
Using the rel=next and rel=prev markups is a good option if you do not have a view-all option or if you prefer to have search engines land on a paginated page. Google uses the markup to detect and index paginated content as a series of pages, rather than as individual pages. Using the markup, Google crawls and indexes as many of the paginated pages as possible. They will then return one page which they think is the most relevant for a search query, usually, it is page one.
An alternative to pagination is an infinite scroll. You, however, need to have an equivalent paginated URL too. Search engines will use the backup paginated URL during site crawling. Using JavaScript ensures that as the user scrolls, the address bar URL adapts according to the paginated URL. The page returned will include “normal” links to the paginated pages, allowing for normal site crawling and site usage.
6. Similar product names
On e-commerce sites, there are products that are very similar, thus having almost the same name, for instance, rose gold cake topper and glitter cake topper. It is very easy for such titles to be identified as duplicates, despite the fact that they refer to different products. The easiest way to resolve this problem would be finding unique titles and product descriptions. Another way would be combining the similar products on one page and allowing the visitor to select the product they want via a dropdown.
The other option is choosing one version of the product to be “canonical”, and the rest of the similar products point to it via the rel= canonical tag. This way, you only write unique copy for the canonical product.
All in all
The above duplicate content SEO ultimate guide looks at how duplicate content comes about, ranging from the web development level to the content creation level, to trying to reach audiences on different platforms or different locations. You need to do a duplicate content analysis on your site from time to time. Once you have identified any issues, the above-discussed solutions will come in handy.